

Comment cultiver l’Intelligence Artificielle dans l’entreprise

Lire aussi : Entretien avec Céline Antonin sur son livre « Le pouvoir de la destruction créatrice »
1. INTRODUCTION
L’intelligence artificielle[1] (IA) est la famille des sciences informatiques qui s’intéresse à la reproduction de comportements que l’on peut qualifier d’intelligents, parce qu’ils résolvent des problèmes complexes de façon adaptative, et qui représentent du point de vue humain un effort cognitif. Dans cet article, nous allons nous intéresser aux conditions qui permettent aux entreprises de tirer le meilleur parti de l’IA. Sans rentrer dans la description détaillée proposée dans le rapport de l’Académie des technologies[2], il est utile de rappeler quelques éléments de cette famille. On trouve par exemple l’approche d’IA symbolique, les techniques de simulation, les différents algorithmes issus de la recherche opérationnelle, mais également tous les outils du traitement du langage tout comme les réseaux sémantiques. L’approche qui reçoit le plus d’attention est l’apprentissage par réseaux neuronaux à couches profondes, appelée deep learning. Le deep learning a fait des progrès spectaculaires en dix ans et c’est aujourd’hui la meilleure approche pour une grande classe de problèmes. Cependant, la boîte à outils du machine learning, contient de multiples autres algorithmes qui permettent à la fois de répondre à des questions précises (prédiction ou catégorisation) ou plus ouvertes.
L’intelligence artificielle n’est pas un enjeu de demain : les technologies d’aujourd’hui apportent déjà des bénéfices et des opportunités de transformation aux entreprises qui les utilisent. Je vous renvoie à l’excellent livre AI + Human [2] ou à mon dernier livre[3] pour avoir un aperçu de ce que la technologie permet de faire dès aujourd’hui. L’IA, en particulier sous la forme d’apprentissage automatique, est appliquée dans l’ensemble des maillons de la chaîne de valeur, tels que la recherche et développement, la production, la supply chain, la vente et la gestion de la relation client. Les méthodes d’apprentissage permettent de reconnaitre des motifs utiles pour la maintenance préventive ou l’assurance qualité. En particulier, les méthodes d’apprentissage automatique jouent un rôle clé pour les algorithmes de recommandation des géants du Web. Les techniques d’assistance intelligente pour la gestion des connaissances s’appliquent à la fois en amont (pour assister la R&D) et en aval (pour assister les clients comme les vendeurs).
Cet article est organisé comme suit. La section 2 s’intéresse à l’adoption de l’IA dans les pratiques de l’entreprise. L’IA est une capacité que l’entreprise développe et déploie pour soutenir ou redéfinir son activité. Le développement de ces solutions implique une transformation profonde, dans l’ensemble de l’entreprise, de la culture digitale et des méthodes de travail. Toute stratégie en IA repose sur une stratégie de données : quelles données sont importantes, comment les collecter, comment les traiter pour faciliter leur mise à disposition ? C’est le sujet de la section 3, comment mettre en place une infrastructure de données qui supporte un processus d’ingénierie des données ? La dernière section ouvre le vaste sujet des compétences qu’il convient de développer pour mettre en œuvre des algorithmes d’IA. Nous allons nous intéresser à trois domaines : les réseaux neuronaux profonds, les techniques d’hybridation, car elles sont la marque de la quasi-totalité des systèmes performants d’aujourd’hui et l’approche système de systèmes.
Lire aussi : L’intelligence artificielle va surpasser les comptables … ou pas
2. PENSER L’INTÉGRATION DE L’IA DANS LA PRATIQUE DE L’ENTREPRISE
2.1 RÉINVENTER LES PROCESSUS ET LES PRODUITS AVEC L’IA
L’intelligence artificielle est une opportunité pour réinventer le développement de produits. Une entreprise qui ignore l’IA verra un de ses concurrents rattraper et inverser son retard en R&D produit parce que sa bonne utilisation de l’IA lui permettra de tirer plus de connaissances métier des mêmes expérimentations ou retours d’usage client. Cette pratique de l’expérimentation est remarquablement expliquée par Jeff Bezos pour qui les entreprises qui ne pratiquent pas l’expérimentation et la valorisation des échecs se retrouvent dans des positions très délicates où elles sont obligées de faire de « gros paris » très risqués. C’est particulièrement le cas pour le couplage intelligent de la supply chain et du demand management. La smart supply chain a besoin des informations en temps réel des demandes clients, et les clients attendent un suivi de leur commande en temps réels.
L’intelligence artificielle est une boucle d’apprentissage avec des humains à l’intérieur. Le rôle des « humains » est multiple: organiser l’apprentissage de la machine (collecter, classer et qualifier les données), participer à son apprentissage, et utiliser la valeur produite par des algorithmes. À côté des cas de systèmes complètement automatisés, la grande majorité des systèmes intelligents sont des systèmes d’assistance, d’aide à la décision. Le co-développement du « centaure » (du couple agent humain et assistant intelligent) est une aventure formidable de réinvention des métiers, et une course à la création de nouveaux avantages compétitifs. L’analyse des solutions mises en place par les géants du web tels que Amazon, Google, Netflix ou Criteo, nous enseigne l’importance de l’ingénierie de la mise en œuvre sur des volumes très importants de données. Au moment où ces entreprises ont commencé, la performance des algorithmes n’était pas très bonne, c’est un laborieux processus d’amélioration continu qui a produit les performances actuelles. Ceci est représenté par la figure 1. Il faut mettre en place un cercle vertueux : plus de données produit plus de pertinence, plus de pertinence entraine plus d’usage et plus d’usage fournit plus de données.
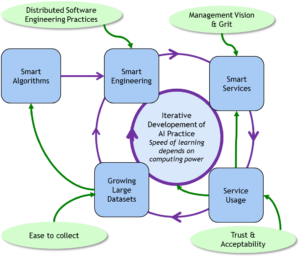 Figure 1 : Le cercle vertueux de l’apprentissage algorithmes/données
Figure 1 : Le cercle vertueux de l’apprentissage algorithmes/données
La mise en place d’applications enrichies par l’IA doit être vue de façon systémique comme une boucle, qui concerne également les acteurs du système. Il y a deux rôles clés pour l’humain dans ce diagramme. Le premier est d’entraîner le système apprenant, et de développer les algorithmes. Le deuxième rôle humain est celui de l’utilisateur. Dans le cadre d’une application B2C, c’est le client du service ; dans le cas d’une application B2B, c’est l’employé qui utilise l’application augmentée par l’IA pour mieux faire son travail – l’opérateur dans une usine par exemple. Prendre en compte l’apprentissage de l’utilisateur est fondamental pour créer de la valeur avec l’intelligence artificielle.
2.2 CULTURE DE DATA LAB
La réussite du développement de l’intelligence artificielle dans une entreprise exige une culture favorable à l’expérimentation. La culture de l’expérimentation est nécessaire en premier lieu parce que l’on ne sait pas à l’avance ce qui va fonctionner comme prévu et créer de la valeur. En second lieu, la culture d’expérimentation permet l’apprentissage et le développement des compétences. Comme pour la plupart des technologies numériques et « exponentielles », il faut faire pour apprendre, et apprendre pour avoir les compétences nécessaires à la véritable création de valeur. L’expérimentation par des équipes transverses « cross-fonctionnelles » est une stratégie distribuée d’exploration de la valeur.
Le modèle du data lab cherche à capturer trois idées : c’est un lieu où différents métiers et compétences travaillent ensemble, c’est un lieu d’expérimentation et c’est un lieu de rigueur scientifique dans la conduite des expériences. Le data lab n’est pas une structure centralisée, c’est plutôt un réseau, précisément à cause de la distribution des opportunités. Le développement des « protocoles » d’apprentissage de solutions demande beaucoup de rigueur et de soin pour construire les assemblages de techniques et vérifier que les résultats obtenus sont robustes et significatifs. Ce point mérite d’être souligné : il est important de faire appel à la data science non pas pour développer ce qui marche, mais pour comprendre ce qui ne marche pas. Le développement progressif et imbriqué, des compétences et de la création de valeur, fait qu’il est nécessaire de suivre une courbe d’expérience. Il faut commencer par les solutions simples, introduire des algorithmes et des méta-heuristiques plus sophistiqués de façon progressive, parce que les méthodes simples fonctionnent bien le plus souvent, et parce que l’analyse des premiers résultats permet de comprendre où porter son effort. De plus, l’utilisation des techniques de visualisation avancées est indissociable du développement des algorithmes d’apprentissage.
3. INTELLIGENCE ARTIFICIELLE ET STRATÉGIE D’ACQUISITION DE DONNÉES
3.1 LE PROCESSUS D’INGÉNIERIE DES DONNÉES
Dans la pratique, une stratégie IA pour une entreprise commence par une « stratégie données ». La définition d’une stratégie des données par les acteurs métiers exige une réflexion et une appropriation : il faut se poser la question de savoir quelles données sont nécessaires et pourquoi. Il y a un effet « poule et œuf » : il faut collecter les données dont on a besoin pour investiguer un problème, et ce que l’on peut faire avec l’IA dépend des données disponibles. Il faut penser les données en tant que cycle continu de collecte : les données du futur ont plus de valeur que celles du passé. La collecte des données doit s’accompagner du processus de qualification des données en produisant des méta-data (des étiquettes qui qualifient les données). La création des jeux de données qualifiées est le point de départ de la plupart des succès d’application de l’IA.
La deuxième étape est la création d’une plateforme d’apprentissage, en construisant des modèles qui sont des représentations de certains aspects des données collectées. Si l’approche deep learning est en général capable d’absorber des masses importantes de données et de laisser l’algorithme décider ce qui lui est utile, les méthodes classiques d’apprentissage demandent un travail de sélection et construction des feature data, qui sont les données retenues dans le modèle. La troisième étape de cette ingénierie des données est de définir rigoureusement le protocole d’apprentissage. Le protocole d’apprentissage explique comment entraîner l’algorithme (le plus souvent, la combinaison d’algorithmes) à partir des données qualifiées, pour produire la meilleure solution pour le problème considéré, à la fois du point de vue de la précision et de la robustesse. Le protocole d’apprentissage est un mélange d’expertise métier, pour définir les bons objectifs qui vont apporter de la valeur à l’entreprise, et d’expertise technique pour produire de façon robuste, par exemple en séparant les données d’apprentissage et les données de test.
3.2 ARCHITECTURE DE DONNÉES
Les algorithmes de deep learning sont capables de reconnaître des défauts ou de participer à l’optimisation des processus, mais il faut disposer d’un historique conséquent pour l’apprentissage. Il faut donc se doter des capacités de stockage, manipulation et enrichissement de ces images ou vidéos. L’architecture de collecte de données doit être ouverte, car il est souvent possible d’enrichir considérablement le modèle sur lequel travaillent les algorithmes en croisant les données de l’entreprise avec des données externes. Cette capacité à collecter l’ensemble des données disponibles dans l’entreprise et à y associer des données externes repose sur l’existence d’un modèle de données métier unique et partagé. Le modèle de données décrit les « objets métiers » : la façon dont la connaissance de l’entreprise est décrite (pour partager une sémantique commune) et organisée (le contenu informationnel des « objets » et les relations qui les relient). Il est important d’avoir un modèle commun et partagé, qui permet de « dé-siloter » les systèmes d’information (supprimer les frontières entre les zones fonctionnelles indépendantes qualifiées de silos) et de s’assurer que les données peuvent circuler sans perte de continuité digitale.
Le système d’information est en premier lieu une plateforme de manipulation de données. L’infrastructure de données couvre les domaines de capture, de stockage, de partage (avec toute la problématique des accès concurrents à la même donnée), de déplacement (parce que les temps de réponses sont importants, il est souvent nécessaire de dupliquer et donc de déplacer les données) et de sauvegarde. La figure 2 décrit sommairement les différents domaines de l’infrastructure de données. L’évolution principale des systèmes d’information est le découplage fort entre le stockage et l’utilisation, avec l’apparition depuis dix ans du concept de « lac de données » (datalake). La deuxième caractéristique de l’infrastructure de données des systèmes d’informations modernes est d’être construite autour du changement. À côté des méthodes classiques qui travaillent sur des « photos » de la situation contenues dans des bases de données, on voit apparaître des méthodes qui analysent les « films » des changements. On parle souvent de traitements à froid (sur les données) et à chaud (sur les changements).
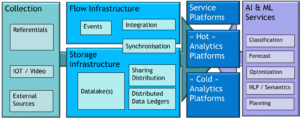
Figure 2 : Infrastructure de données
4. ACQUÉRIR UN LARGE SPECTRE DE COMPÉTENCES
4.1 LE DEEP LEARNING ET SON HYBRIDATION AVEC DES MÉTA-HEURISTIQUES
Les réseaux neuronaux profonds[5] ont permis à l’intelligence artificielle de sortir de plusieurs décennies de quasi-stagnation sur des tâches élémentaires de reconnaissance, qu’il s’agisse d’images, de textes ou de sons. Les réseaux neuronaux profonds s’appliquent à un large éventail de problèmes de reconnaissances de motifs ou de situation, au-delà de la perception, par exemple dans le monde de la finance en gestion de portefeuilles ou dans le digital manufacturing pour diagnostiquer des situations préoccupantes. En revanche, pour réussir à entrainer ces réseaux sur des problèmes difficiles, il faut beaucoup de puissance machine, beaucoup d’exemples qualifiés et une bonne expérience pratique. L’explosion de la puissance machine est derrière la plupart des progrès décisifs, à la fois comme conséquence de la loi de Moore et parce que des architectures plus optimisées, telles que les GPU puis les TPU se sont généralisées (Graphical Processing Unit et Tensor Processing Unit, par opposition au CPU, Central Processing Unit, qui est puce principale de nos ordinateurs). Kai-Fu Lee fait de l’accès massif aux données la première condition de succès et de domination sur ses concurrents dans l’application de l’IA [6]: « Si vous avez beaucoup plus de données, un algorithme conçu par une poignée d’ingénieurs en IA de niveau normal donnera en général des meilleurs résultats que ce qu’obtiendrait un spécialiste de niveau mondial avec moins de données ». Pour autant, le deep learning n’est pas une panacée, et il ne se substitue pas aux autres techniques de l’intelligence artificielle. Les réseaux profonds construisent des algorithmes « en boîte noire », dont nous ne savons pas expliquer les décisions. Pour certains problèmes (placer une publicité ou recommander un shampoing) ce n’est pas rédhibitoire, mais dans d’autres cas, cela pose un problème de confiance et d’éthique (prescrire un traitement médical ou conduire une voiture au milieu des piétons).
L’intelligence artificielle est un riche ensemble de méthodes qui sont le plus souvent utilisées de façon hybride. On trouve des exemples d’hybridation (combiner deux approches ou plus dans la boîte à outils évoquée en introduction) dans la plupart des réussites spectaculaires, qu’il s’agisse de AlphaGo, IBM Watson, ou Todai Robot, le logiciel de l’université de Tokyo qui est capable de réussir un concours d’entrée à l’université. Une autre forme d’hybridation très intéressante est la combinaison de l’exploration aléatoire pour générer des données avec l’intelligence artificielle. Ces approches « génératives » permettent d’explorer des nouveaux domaines de conception. Il existe de multiples façons d’utiliser et de combiner les algorithmes « élémentaires » de la boîte à outils. L’intelligence artificielle, tout comme la recherche opérationnelle, a produit de multiples méta-heuristiques depuis des dizaines d’années, qui jouent un rôle clé pour construire des solutions hybrides.
L’apprentissage par renforcement (reinforcement learning) est une technique très ancienne de l’IA, fondée sur une boucle d’amélioration continue par sélection de petits changements incrémentaux grâce à une fonction de « récompense ». Libratus, le champion du monde de Poker développé à l’université Carnegie-Mellon, est une combinaison d’apprentissage statistique classique et de reinforcement learning. Les méthodes probabilistes (telles que l’approche Monte-Carlo) et leur déclinaison sous forme de communautés massives d’agents sont essentielles pour explorer des espaces de recherche, ce que montrent les exemples de Deepmind (depuis AlphaGo à AlphaFold). Le monde de l’apprentissage profond a produit lui aussi différentes « méta-heuristiques » comme le transfer learning qui permet de réutiliser un apprentissage « des couches basses », obtenu sur un très grand volume de données génériques, sur un nouveau réseau que l’on va entraîner avec un plus petit nombre d’exemples spécifiques au problème que l’on veut traiter. La notion de réseau « adversaire » (GAN : Generative Adversarial Network) cherche à améliorer la robustesse des réseaux profonds (qui sont souvent mis en échec par une petite variation) en construisant une paire de réseaux neuronaux, le second cherchant des contre-exemples à l’apprentissage du premier, pour construire par renforcement un système global plus robuste. Ce qu’il faut retenir de ces quelques exemples, c’est qu’il est important d’avoir une vision large de l’IA[7], et de se maintenir « à jour » de l’état de l’art à la fois en termes d’outils et de méthodes de composition.
4.2 SYSTÈMES DE SYSTÈMES
La combinaison de différentes techniques d’IA peut se faire par hybridation, mais elle peut également se faire par assemblage, sous la forme de systèmes de systèmes. Dans un système de systèmes, chaque composant peut faire appel à des techniques différentes pour collaborer sur un but commun.
Je vais terminer en illustrant cette approche par l’exemple d’un robot autonome, qui est illustré dans la figure 3. Ce robot est placé sur une ligne de production, il collabore à la fois localement avec des humains et d’autres robots, mais également de façon globale avec d’autres robots identiques placés sur d’autres lignes ou d’autres usines. La figure illustre quelques exemples de sous-systèmes intelligents qui forment collectivement le logiciel du robot, en lui permettant de combiner un apprentissage individuel et un apprentissage collectif (ce que Tesla cherche à faire sur l’ensemble de ses voitures connectées). La partie du bas de la figure est consacrée à l’apprentissage individuel, autour d’une organisation « classique » : Décision-Buts-Planification-Exécution. Cette boucle s’appuie sur une intelligence situationnelle du robot nourrie par les capteurs et les algorithmes associés de reconnaissance de situation. C’est bien sûr ici que l’on va utiliser la puissance des réseaux neuronaux, tandis que des approches d’IA « symbolique » restent très pertinentes pour la boucle de contrôle. L’architecture illustrée ici fait également apparaître un module de « réflexes », en reproduisant un modèle biomimétique en couches, qui sont des circuits courts de réaction aux situations. Dans une situation opérationnelle réelle, l’IA d’un module de réflexe doit être certifiable.
Ce qui caractérise l’intelligence, comme le souligne Yann Le Cun, ce n’est pas juste la réaction à l’environnement mais l’anticipation. Notre robot autonome doit donc disposer de capacités de prédiction, ce qui suppose une mémoire de ses expériences passées, ainsi que d’un modèle de fonctionnement de son environnement interne et externe. L’architecture illustrée sur la figure 3 représente la boucle d’ajustement continue du modèle de fonctionnement interne en comparant la réalité et ce qui est obtenu par le modèle de prévision. Cette construction du modèle « du monde externe » peut facilement se concevoir de façon collaborative pour associer les autres robots identiques, ce qui est illustré sur la partie haute de la figure. L’approche système-de-systèmes dessinée ici permet au robot de combiner son apprentissage individuel avec des éléments (règles de comportement mais surtout règles d’évaluation de situation, un autre bon exemple d’application des réseaux neuronaux) fournis par sa communauté.
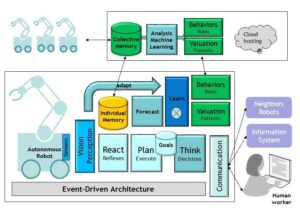
Figure 3 : Approche Système de Système
5. CONCLUSION
L’IA est une discipline ancienne, mais dont les capacités se sont considérablement accrues depuis 10 ans. Les entreprises doivent se saisir de l’opportunité de réinventer leurs processus, leurs produits et leurs solutions. Cette transformation, qui s’inscrit dans la transformation digitale des entreprises[4], est complexe : elle touche la culture, l’organisation et les savoir-faire. Cet article est une modeste contribution pour souligner trois aspects :
- Le développement de l’IA dans les pratiques de l’entreprise est une « révolution de l’intérieur », distribuée sur l’ensemble de l’organisation.
- L’IA est, d’un point de vue pratique, une modalité logicielle des outils de l’entreprise. La fondation de cette transformation est la stratégie de données, depuis la vision métier jusqu’au développement d’une infrastructure moderne de données.
- L’IA est un domaine riche, en évolution constante, qui exige une approche d’apprentissage continu des connaissances. Les deux mots clés de cette approche sont « expérimentation » – apprendre par la pratique – et « ouverture », savoir utiliser les outils et les compétences des autres, et surtout ne pas se laisser enfermer dans une conception trop étroite de ce qu’est l’Intelligence Artificielle.
Lire aussi : Less is Moore
6. BIBLIOGRAPHIE
[1] RUSSEL S. & NORVIG P., Eds., Artificial Intelligence: A Modern Approach, Prentice Hall Series, 2002.
[2] « Renouveau de l’Intelligence Artificielle et de l’Apprentissage », Rapport Académie des technologies, 2018.
[3] DAUGHERTY P, WILSON H.J., Human + Machine: Reimagining Work in the Age of AI. Harvard Business Review Press, 2018.
[4] CASEAU Y., L’approche Lean de la transformation digitale – Du client au code et du code au client, Dunod, 2020.
[5] GOODFELLOW I., BENGIO Y. & COURVILLE Y. (2016), Deep Learning, MIT Press, 2016.
[6] LEE KAI-FU., AI Super-Powers – China, Silicon Valley and the New World Order. Houghton Mifflin Harcourt, 2018.
[7] FORD M., Architects of Intelligence: The Truth about AI from the people building it. Packt Publishing, 2018.
Cet article a été initialement publié sur le site variances.eu le 14 septembre 2020. Il est repris par Vox-Fi avec due autorisation. Cet article a été publié sur Vox-Fi le 28 septembre 2020.


