

« Le Bon, la Brute, et le Truand » dans le bouillonnement du Big Data. Un trio innovant pour créer de la valeur
Pour illustrer l’expression « Big Data », je citerai Eric Schmidt, le PDG de Google, qui évoquait dans une conférence en 2010, que «chaque jour, le monde produit autant d’informations qu’il en a généré depuis l’aube de la civilisation jusqu’en 2003 ». Les entreprises s’intéressant exponentiellement à cette nouvelle capacité à transformer les données en production de valeur, il n’en fallait pas plus pour que la quasi-totalité des secteurs d’activité ne se lance logiquement dans de nouveaux métiers. Essentielle à la prise de décision des managers, la « data science » s’est même invitée dans les écoles qui les forment, à côté de « l’accounting management ».
La « Data », une matière première inépuisable.
La donnée prend naissance brute, dépourvue de tout raisonnement, va pouvoir servir de base à une analyse plus élaborée, et devenir une véritable valeur de transformation. Cette approche élémentaire de la donnée montre aussi bien le caractère inépuisable de sa production que celui aléatoire de son intérêt. Dans le domaine du business, les données qui vont nous intéresser peuvent se classer en trois catégories : Les données relatives aux clients, aux processus internes, et à l’internet des objets connectés.
Le « Big Data », ce n’est pas que de l’intox.
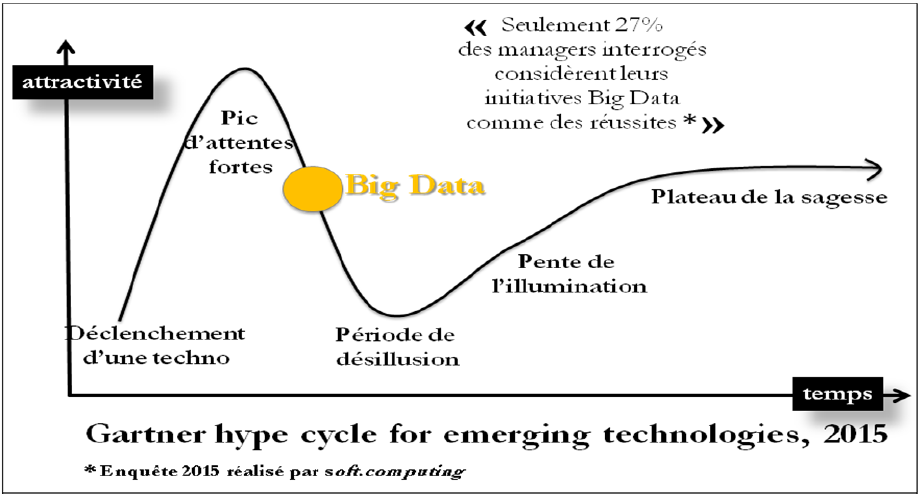
Le Big Data n’échappe pas au buzz médiatique, et cela me rappelle le fameux « Bug de l’an 2000 » qui avait généreusement rempli les caisses des SSII, avant d’accoucher d’une souris. Plus récemment, on a fait de l’appellation « Cloud » une formidable opération marketing, alors que le « Cloud » ne désigne qu’un simple coin du « Web » dans lequel on héberge l’externalisation des serveurs informatiques des entreprises ! En opposition avec cet engouement médiatique, une étude du think tank EBG montre que moins d’une entreprise sur cinq en revendique l’utilisation effective, et seul un dirigeant sur quatre est à même d’en donner ne serait-ce qu’une définition précise. Ce concept est tantôt présenté comme une « potion magique » aux vertus curatives de tous les maux de la macro-économie, tantôt comme un robot « ideas’ shaker » dont la technologie prendrait le pouvoir sur l’homme. De fait, le Hype Cycle 2015 du Gartner group positionne le Big Data au milieu de la plongée dans la vallée de la désillusion, sur sa courbe d’adoption des nouvelles technologies.
On peut définir le Big Data comme étant une « nouvelle capacité à gérer, traiter et analyser une explosion du volume des données ». Ce concept de données massives peut se réduire à trois dimensions :
– La Vitesse, du batch au real time, est liée à l’explosion des demandes de traitement et au rythme du flux entrant.
– La Variété s’étend des données complètement structurées des « champs » informatiques des systèmes anciens, jusqu’aux données non structurées du langage naturel des emails, des sms et autres tweets.
– Le Volume des données massives jongle avec des unités habituelles, le méga, le giga et le téra, mais aussi avec des unités rarement utilisées; sauriez vous convertir par exemple le péta, l’exa, le zetta ou le yotta ? Il va falloir s’y mettre, même si l’on n’est pas data scientist…
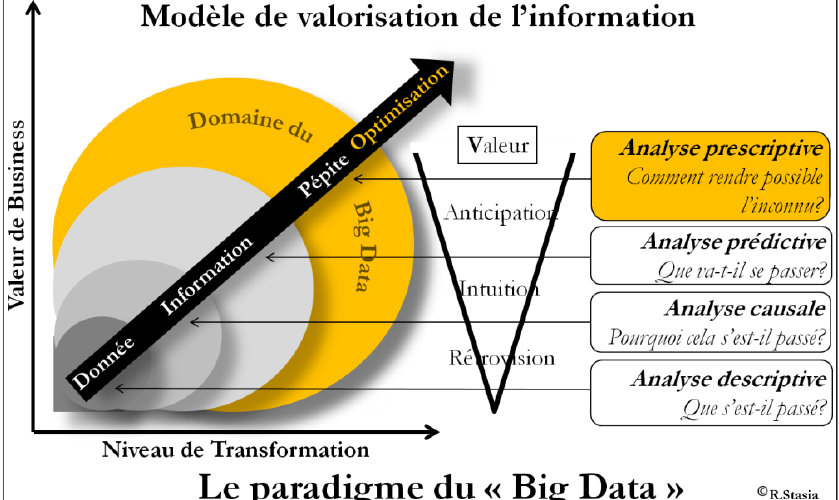
Dans sa dynamique d’instrument d’analyse, le Big Data présente un quatrième « V », celui de la Valeur, et va profondément affecter le monde de la conception, de l’innovation et du marketing. On peut même parler de révolution, puisque le Big Data permettra le pilotage de la performance en tirant partie du déluge des données, assuré par l’Internet, les smart-phones et les objets connectés. Cette Valeur est quelque part, prête à émerger d’un réservoir illimité de données, classées en quatre catégories.
1. « Je sais ce que je sais », classe de données à faible volume et faible variété.
2. « Je ne sais pas ce que je sais », classe de données à fort volume et faible variété.
3. « Je sais ce que je ne sais pas », classe de données à faible volume et forte variété.
4. « Je ne sais pas ce que je ne sais pas », classe de données à fort volume et forte variété.
Pour illustrer le potentiel de la catégorie reine, la quatrième, citons qu’il a fallu attendre plus de 210 ans pour inventer la valise à roulettes, entre l’invention du patin à roulettes par John Joseph Merlin dans les années 1760 et l’invention de la valise à roulettes en 1972 par Delsey. Et bien, avec le Big Data, plus jamais çà !
Le « Big Data » : qui fait quoi ?
Au fond, il propose un nouveau modèle de valorisation de l’information et de son management, qui permet de bien comprendre les rôles et attendus de chacune des parties prenantes de l’entreprise au regard du Big Data. Loin d’être « un bon, une brute et un truand », le trio d’acteurs décrit ci-après est appelé à jouer un rôle déterminant.
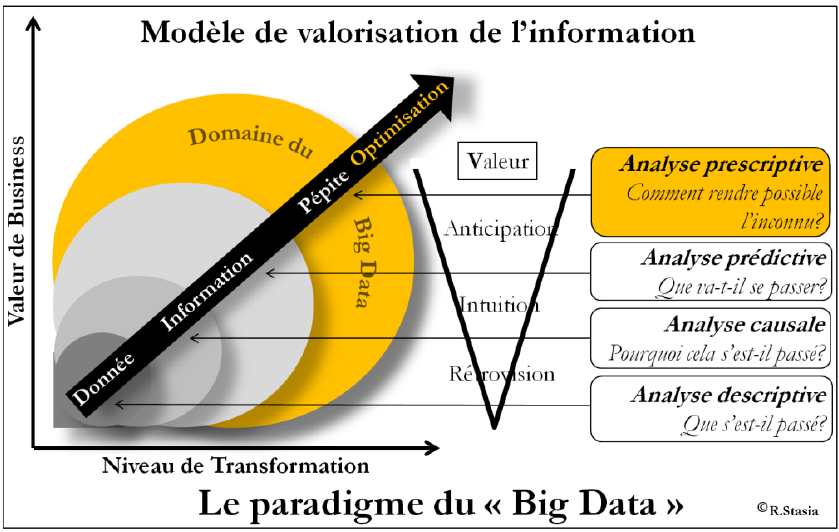
Le data scientist va « tout simplement » rendre possible, non pas l’impossible, mais… l’inconnu. Pour lui, la data c’est son « dada » ! Cet ingénieur d’un nouveau type, aux compétences totalement différentes de celles d’un ingénieur informaticien, est l’oiseau rare que cherchent à dénicher toutes les entreprises qui lancent un projet Big Data. Il va travailler sur les problématiques de modélisation, à partir des mathématiques appliquées aux bonnes données. Il existe plusieurs profils parmi lesquels on peut citer : le business data scientist, capable d’évaluer les risques et l’incertitude entourant les décisions managériales, l’IT data scientist, capable de faire le pontage avec les métiers pour vulgariser l’approche, le computeur data scientist, capable de manipuler et d’organiser les énormes quantités de données. Nous sommes encore très loin du robot-shaker automatique et intelligent, d’où sortiraient prémâchées toutes les idées d’innovation à fort potentiel business.
Le marketeur va systématiser la définition des besoins-clients à partir de données, analysées, croisées, et relatives à l’usage et à l’expérience client. Pour lui, la data massive est une révolution culturelle. En effet, elle fait voler en éclats les modélisations du comportement des consommateurs précédemment mis en équations à partir de données classiques. L’avènement du e-commerce a généré les « cookies », une race d’espions bien plus redoutables que l’exploitation indiscrète d’un ticket de caisse! Un point extrêmement important pour les directions marketing consiste à ne pas mettre à la corbeille leurs anciens modèles pour les remplacer par les nouvelles informations apportées par les « cookies ». Elles doivent d’abord effectuer un changement de base, en reprenant les données ayant inspiré leurs modèles actuels, puis en les faisant retraiter par les instruments du Big Data; en effet les outils Hadoop, NoSQL, ou encore Memtables lisent parfaitement le format pdf.
Le contrôleur de gestion va grandir dans son métier, en passant progressivement de la prévision à la prescription. Pour lui, la data est sa matière première historique, et la data massive est potentiellement un accélérateur de son intégration dans le processus des opérations contrôlées. Lorsqu’il se contente de décrire le passé, il est en « gestion rétroviseur » et on le compare souvent à un « reporter » sans valeur ajoutée business; lorsqu’il passe au stade supérieur, en faisant de l’analyse causale des écarts, on lui dit qu’il a simplement « fait son travail » permettant de déclencher des plans d’actions correctives; quand les reprévisions sont mises en place, il peut atteindre le grade de « business partner ». En franchissant l’étape du Big Data, il va fortement contribuer à la prescription du futur, grâce aux traitements du data scientist et à la vision prospective du marketeur. Une façon pour lui, peut être, de devenir définitivement « le bras droit » de la direction générale !
Le « Big Data » : stratégie ou outil ?
Il est totalement inutile de se lancer dans un projet Big Data si l’on n’a pas préalablement déterminé des objectifs concrets, qui se traduiront précisément dans le compte de résultat. Le danger est de se laisser leurrer par les espérances d’un mot clef, sans que l’entreprise n’ait une vision claire de sa traduction dans son business. Trouver les cas d’usage est la première des trois conditions de réussite d’un projet Big Data, à laquelle il convient de rajouter de convaincre la DG avec des ROI conformes aux attentes; la mise de fonds initiale d’un premier projet Big Data est en effet souvent plus coûteuse que prévu, et plus élevée que celle des projets suivants. La troisième condition de succès est de rendre le projet implémentable dans le système d’informations. Une fois démontré l’intérêt d’un projet basé sur le traitement de la donnée, le plus délicat consiste à déterminer quelle est la data qui générera le plus de valeur dans le cas d’usage retenu. Pour paraphraser Bill Schmarzo, CTO de emC et auteur de « Big Data: Understanding how data powers Big Business », « les entreprises n’ont pas besoin d’une stratégie pour exploiter les Big Data ; elles ont besoin d’un business plan qui intègre les données et les possibilités ouvertes par les Big Data dans un univers digital. » Ouf ! La stratégie à retenir est bien celle de l’entreprise, éventuellement structurée dans un balanced score card, mais reste surtout déclinée dans un « bon vieux » business plan, dont seulement certaines actions relèveront du Big Data.


Vos réactions
Bonjour,
Article intéressant permettant de revenir sur des concepts pas ou peu maitrisès de beaucoup.
L’arrivée du big data est principalement lié aux données non structurées (texte, image, vidéos) que nous pouvons traiter maintenant grâce à la technologie cognitive.
4 acteurs communiquent largement sur ce sujet.
Report comment